
TCPはなぜ速いのか
インターネット上で使われている主なトランスポートプロトコルには、TCPとUDPがあります。近年はQUICなどのUDPベースの通信が増加していますが、依然としてTCPが大部分を占めています。
UDPは非常にシンプルなプロトコルで、基本的にはポート番号による接続アプリケーションの指定以外はなく、ヘッダーもポート番号の他はデータ長とチェックサムだけです。
一方でTCPはコネクション型のセッション管理や到達保証、それを実現するためのパケット再送など、多くの機能を持ちます。
そのため、直感的にはTCPよりUDPの方がオーバーヘッドが少なく、単純な通信速度ならUDPの方が速くなりそうに思えます。しかし、実際の通信速度は、ほとんどの場合でTCP > UDPとなります。
以下は、100Gbpsの帯域を持つ環境で、ネットワーク速度計測ツールであるiperf3を使ってTCPとUDPを計測した結果です。
iperf3によるTCPの計測結果
[ ID] Interval Transfer Bitrate Retr [ 5] 0.00-10.00 sec 37.0 GBytes 31.7 Gbits/sec 0 sender [ 5] 0.00-10.04 sec 36.9 GBytes 31.6 Gbits/sec receiver
iperf3によるUDPの計測結果
[ ID] Interval Transfer Bitrate Jitter Lost/Total Datagrams [ 5] 0.00-10.00 sec 14.4 GBytes 12.4 Gbits/sec 0.000 ms 0/1732579 (0%) sender [ 5] 0.00-10.04 sec 12.7 GBytes 10.9 Gbits/sec 0.024 ms 205328/1732512 (12%) receiver
それぞれ同じ環境(Xeon E5-2630 v4の2台のPC間)で計測したものですが、TCPは約30Gbps、UDPは約12Gbps(到達した分は約11Gbps)となり、2倍以上TCPの方が速い結果となっています。このような結果になった理由は、UDPよりTCPの方が処理負荷が低かったためです。
TCPの処理負荷が軽い理由
TCPがUDPより処理負荷が低い理由の1つとして、1度に多くのデータをまとめて処理できることが挙げられます。UDPはデータグラム型と呼ばれるパケット単位での処理が行われるのに対し、TCPはストリーム型で、内部的にはパケットサイズより大きな単位でデータを処理することができます。これは特に、OS内部でユーザ空間とカーネル空間の間で行われるデータのコピーや、ネットワークレイヤー間のパケットの受け渡しの回数を減らすことにつながり、処理負荷を大きく減らすことができます。
そのほかの理由として、TCPの処理を高速化するための物理的なチップが、多くのネットワークカードに搭載されており、そこで処理の一部をオフロードすることで高速化していることも挙げられます。TCPはストリーム型であるために処理負荷を低減できると述べましたが、その代わりにパケットを分割・結合する必要があり、本来は逆にオーバーヘッドが増えてしまいます。しかし、ネットワークカードにパケットの分割・結合処理をオフロードするため、そうした性能上のデメリットを無くし、全体として高速に処理できるようにしています。
TCPの輻輳制御
TCPは、ネットワーク上の空き帯域に合わせて送出量を制御する機構を持っています。大まかな原理としては、TCPはデータを即時送信可能な量を定義するウィンドウバッファというバッファを持ち、このウィンドウバッファの大きさを変化させることで送出量を制御します。基本的には、送信すべきデータでウィンドウバッファが一杯になっている状態では、対向側から応答パケットを受け取るたびに、徐々にウィンドウバッファサイズを大きくしていきます。そしてパケットロスなどによって輻輳の発生を検出すると、ウィンドウバッファサイズを小さくします。
こうした制御を適切に行うことで、パケットロスの発生を抑制し、結果的に通信速度を向上させることができます。
このウィンドウサイズの変化のさせ方を決める輻輳制御アルゴリズムにはいくつかの種類があります。
輻輳制御アルゴリズムに関する詳しい内容は別途記事にする予定です。
TCPのペースコントロール
TCPのウィンドウバッファによる輻輳制御は、もう1つ、重要な性能面での恩恵があります。
それは送出されるデータのペースコントロールで、TCPの輻輳制御が適切に行われていると、パケットとパケットの間隔が均等になります。
原理としては以下のようになります。
もし、最初にパケットとパケットの間隔が詰まった状態でまとめて送信してしまったとしても、対向側に到達する時は、間の経路の最も帯域が遅い部分に合わせて間隔が空きます。(この時、最初の送出間隔が適切でないことが原因でパケットロスが発生して速度低下する恐れがあります)。すると、対向側からの応答パケットは、到達した時のパケットの間隔に合わせて返答されます。そして、送信側は、対向側から応答パケットを1つ受け取るたびに、ウィンドウバッファサイズを徐々に(多くの場合、1応答パケットに対してウィンドウバッファサイズを1パケット分)大きくしていきます。ウィンドウバッファサイズが大きくなると、次の瞬間にはその分増やした量のパケットが送信されます。
このようにして、応答パケットを起点としたウィンドウバッファの増加による送出量の制御は、結果としてネットワーク帯域に対する適切なパケット間隔を実現することになります。
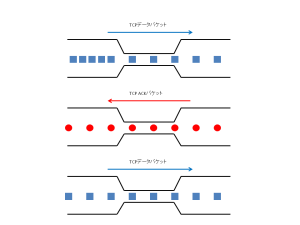
このようなペースコントロールのやり方が優れている点は、高スループット時でも少ない処理負荷で対応できることです。もし、パケットの送出間隔を他の方法で制御しようとした場合、最も単純な方法は1つパケットを送信するごとにsleepなどのタイマーを設定することですが、これはスループットが小さい時しか適切に動作しません。
例えばMTU1500で1Gbpsの通信を行う場合、1秒間に約10万パケット近くが流れます。この時のパケットの間隔は、約10マイクロ秒です。1Gbpsではなく10Gbpsや100Gbpsだった場合は、1マイクロ秒や100ナノ秒になります。
一般的には、OSのユーザ空間上で利用できるsleep関数の精度は、良くても1ミリ秒です。それ以上の精度を出すためには、sleepではなくビジーループを使うなどの工夫が必要になります。そのため、ソフトウェア的に実現するパケットのペースコントロールの精度はあまり良くないことが多いです。(WindowsのOSの標準の帯域制御機能など)
TCPのペースコントロールは、sleepなどのタイマーは使わず、応答パケットを受信することによる割り込みを起点として動作します。そのため、最小限の処理負荷で、マイクロ秒やナノ秒の精度でパケット間隔を制御することができます。
TCPはなぜ遅いのか
ここまで、TCPの速度が速い理由を簡単に述べましたが、実際の通信では、TCPの速度が大きく低下することがあります。
その原因は主に、ネットワーク上の遅延とパケットロスです。
以下は、遅延装置を使って100msの遅延と10%のパケットロスを入れた時のiperf3の計測結果です。
[ ID] Interval Transfer Bandwidth Retr [ 4] 0.00-10.00 sec 3.27 MBytes 2.74 Mbits/sec 32 sender [ 4] 0.00-10.00 sec 2.96 MBytes 2.48 Mbits/sec receiver
スループットの単位がGbits/secからMbits/secに変わっており、約1万分の1まで速度が低下しています。
TCPがパケットロスによって大きく性能が低下する理由は、TCPのパケット再送能力の限界と、それを前提とした輻輳制御アルゴリズムによるものです。
TCPはパケットロスが発生すると、それを送信側に通知し、どの部分が抜け落ちているかを知らせます。この通知方法は、初期のバージョンのTCPの場合はTCPヘッダの応答シーケンス番号を連続で同じものを返すという方法で、1度に1つのパケットロスしか通知できませんでした。そして後のバージョンでは、SACK(selective acknowledgement)と呼ばれる拡張機能で、複数のパケットロスを通知できるようになりましたが、TCPヘッダそのものの長さの限界(可変長で最大64byte)があり、SACKで通知可能なパケットロスも最大4つまでとなっています。そのため、一度に大量のパケットロスが発生するとTCPは再送が適切に行えなくなり、通知しきれないパケットロスに関しては、本来再送しなくても良い部分も含めてまとめて再送するという形になってしまいます。
そうした余分な再送が起きるとネットワーク全体の利用効率が低下するため、TCPの輻輳制御アルゴリズムは、一度に大量のパケットロスが発生しないように、パケットロスを検出するたびにウィンドウバッファを大幅に小さくすることで、輻輳ロスを減らそうとします。その結果として、パケットロスが恒常的に発生するネットワーク環境では、極端にスループットが低下することになります。
なお、遅延が大きい環境では、上記のパケットロスによる性能低下がより顕著になります。単純に、遅延が2倍になれば、パケットロスによる性能低下も2倍になります。これは、パケットロスを検出して再送されるまでに掛かる時間が遅延量に準ずることと、輻輳制御アルゴリズムによるウィンドウバッファの変化の速さも遅延量に準ずるためです。
TCPの問題点の改善
こうした遅延やパケットロスに弱いというTCPの特徴に対し、それを改善した通信プロトコルが、xTCPやHpFPとなります。
これらのプロトコルについて、別の記事で解説する予定です。